Decoupling Human Characteristics from Algorithmic Capabilities

[This report was commissioned by the IEEE Standards Body and was published in January 2021 — The report can be accessed on IEEE or on Slideshare.]
Executive Summary:

The prevalence of attributing human traits to Artificial Intelligence-Systems in efforts to describe its capabilities and use-cases does not adequately represent the technology in a sufficient way to allow for decision makers to fully engage with the ethical questions they are accountable for. Nor does this anthropomorphization effectively communicate the risk and liability involved with AI-Systems.
This report argues that the way we use language to express AI-Systems use-cases and capabilities plays an important role for decision makers to be able to have the leadership agency they need to make important decisions on a technology that will have wide-spread implications, opportunities and consequences for their organization and for others outside it.
The following pages dissect the most commonly ascribed human traits to AI-Systems and with an intent to de-couple them from technological capabilities in efforts to reduce ambiguity.
The hope is that this document will assist decision-makers, legal counsel and those who support them to be more empowered in their conversations about AI-Systems with technologists and their organizations
Where we are today
This turn of the century has brought about an explosion of new technologies across several fields of science. One that has notably affected our daily lives and economies has been the advancements in the field of computer science which has brought about the internet. Most recently we are starting to see artificial intelligence (AI) follow a similar pattern in adoption, market penetration and impact in our daily lives. As the internet gained critical mass, companies had to learn what it was, how it worked and what it meant for their business. Today we are in a similar situation with AI, however the answers to what it is, how it works and what it means for business (and our daily lives) are more complex.
This is the first technology that has the potential to rival our human ability to learn, analyze, acquire knowledge, conduct foresight and make decisions. In doing so it upends labor as we know it, re-calibrates the agency we have on our body, challenges our understanding of the world and our relationship with others. In an effort to communicate the capabilities of artificial intelligence, evangelists, technologists and sales representatives have tried to make parallels with human capabilities. In doing so, they used vocabulary that was characteristic of humans; and this is where the proliferation of anthropomorphic language in the communication of artificial intelligence began. It has been successfully perpetuated by Hollywood in movies such as Her[1], and Ex-Machina[2], as well as in AI agents such as Amazon Alexa who have a wide range of ‘skills’[3] that can be downloaded.
The use of anthropomorphic words such as learning, seeing, hearing and understanding are
useful to quickly communicate AI product capabilities for elevator pitches or short trade-show conversations. However, these words are not effective in communicating the actual capabilities of what the convergence of data, algorithms, machine, statistics and math are offering. This anthropomorphic language has expanded outside the boardroom and convention centers and into daily conversations. The problem with attributing human characteristics to AI is that it masks important nuances that need to be understood and discussed, if not, we — individually, collectively and socially lose our agency to engage in a constructive conversation about the many components of the algorithmic supply chain which warrant an informed civic debate and a deep understanding of risk and liability by corporations and governments.
This report aims to open a conversation about de-coupling anthropomorphic language from discussions around artificial intelligence in efforts to give agency to the public and decision makers. The paper offers alternative non-anthropomorphic vocabulary through the lens of five commonly used words which attribute human and super human capability to AI: Learn, Analyze, Knowledge, Foresight, and Decision-Making. It is the hope that unpacking these elements will help avoid mis-association traps and build more constructive conversational bridges between decision makers, technologists, legal advisors, engineers and the public.
However, the starting point in this report is the words “artificial intelligence” themselves.
Intelligence Cannot be ‘Artificial’
What is artificial intelligence? The term itself already has an important human characteristic — intelligence. Terming it as artificial creates expectations and assumptions about the intelligence capabilities in relation to human intelligence.
The IEEE Global Initiative for Ethical Considerations in Artificial Intelligence and Autonomous Systems launched the ‘Ethically Aligned Design’ initiative to create a collective vision to prioritize human well-being in the development of artificial intelligence. In their latest Ethically Aligned Design report they addressed the anthropomorphic term and noted a terminology update to the term Artificial Intelligence, which they now term as Autonomous and Intelligent Systems (AIS). The report explained that “there is no need to use the term artificial intelligence in order to conceptualize and speak of technologies and systems that are meant to extend our human intelligence or be used in robotics applications.” In this sense, AIS better encapsulates the multiple fields involved: machine learning, intelligent systems, engineering, robotics etc. [4].
The Organization for Economic Co-operation and Development (OECD) has also taken a systems based approach in their AI Principles effort which focuses “on how governments and other actors can shape a human-centric approach to trustworthy AI.” The term they use is AI-Systems which they define as “ a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations, or decisions influencing real or virtual environments. AI systems are designed to operate with varying levels of autonomy.” [5]. The systems approach was also favored by the European Commission’s High-Level Expert Group on Artificial Intelligence which has adopted the term AI-Systems. [6].
The systems based approach to the term AI-Systems is an ideal term to interpret artificial intelligence because it avoids creating the perception that there is a new ontological entity of intelligence. Instead, AI-Systems indicates that it is a type of system which is different from other systems; vice a type of intelligence which is different to human intelligence.
This report adopts the OECD definition and from this point on uses the term AI-Systems instead of artificial intelligence.
De-coupling Anthropomorphic Language from Algorithmic Function

The power of words has been leveraged by poets, politicians and many others who sought to effectively communicate their message. Words are equally important for technologists, and considering the rapid technological change across all fields of science, effective technology communication is arguably the most important imperative for an informed and inclusive civic debate. AI-Systems are no exception.
The words used to describe AI-Systems and their capabilities shape the way we understand them and also play a role in our expectations of their performance. As such, the report aims to offer clarify the algorithmic meaning of the human characteristics that have been ascribed to algorithms. This will be explored through the lens of the following human characteristics which are commonly attributed to AI-Systems: Learn, Analysis, Knowledge, Foresight, and Decision-Making.
LEARN

The most widely used human characteristic to describe an element of artificial intelligence is ‘learning’. Technologists attempt to explain to the public and decision-makers that AI-Systems learn from data and that machine learning is an important tool to acquire actionable insight from an organization’s data.[8] While the use of a human capability is a relatable way to understand some aspects of AI-Systems, it can be problematic in understanding the nuances of what it means in terms of algorithmic and machine capability.
Unpacking the supply-chain of learning is very helpful in communicating how AI-Systems learn.
- Starting with data. What data is used? What format is it in? How has it been collected? How has it been labeled? Is it structured data, or unstructured data? These questions are more accessible to explain to those who are not working with statistical analysis and algorithmic design. Once it is clear what data (or information) will be leveraged by the algorithm, then a discussion can occur regarding the algorithms intended purpose. Starting the learning conversation with data allows for transparency in where the data comes from, which also allows for questioned scrutiny. For example, some sensors or machines are not as accurate as others that collect the same data. This may or may not be a liability for an organization.
Similarly, once decision-makers can be made aware of what data is included and what isn’t, it can allow for a conversation about missing data that is relevant. For example, if someone is collecting data about a particular port to understand the shipping movement, a decision-maker may ask the technologist about the inclusion of weather data because this is a vector that plays a role in how a port manages the cargo ships that come in and out. The result — more agency in the data basics that inform an algorithm. - Algorithmic Purpose. What is the algorithm meant to process? And to what end? This is where we can start to dissect the intents of ‘learning’. Is the algorithm meant to process data in efforts to establish a baseline? Is it meant to identify patterns? Anomalies? Or perhaps classify information? These nuances are important for the decision-maker to understand how the algorithm is relevant for their needs, as well as to more effectively communicate to technologists or sales representatives the organization’s intended use and concerns.
- Algorithmic Development. As decision makers and lawyers seek to further understand algorithmic risk technologists will need to better communicate how the algorithm works. While there are some cases where technologists are unclear how algorithms came to the conclusions they did, it is still possible to explain and defend the chosen methodology for the algorithm. In this space the word learning is used in several ways, most notably with: machine learning, and deep learning. Unpacking machine learning through machine characteristics will help decision makers and lawyers better ascertain how the algorithm works, ask questions about risk and further assess the utility of a machine learning algorithm in one’s organization. Traditional programming is a useful comparative example in this case. The below graphic illustrates the difference:
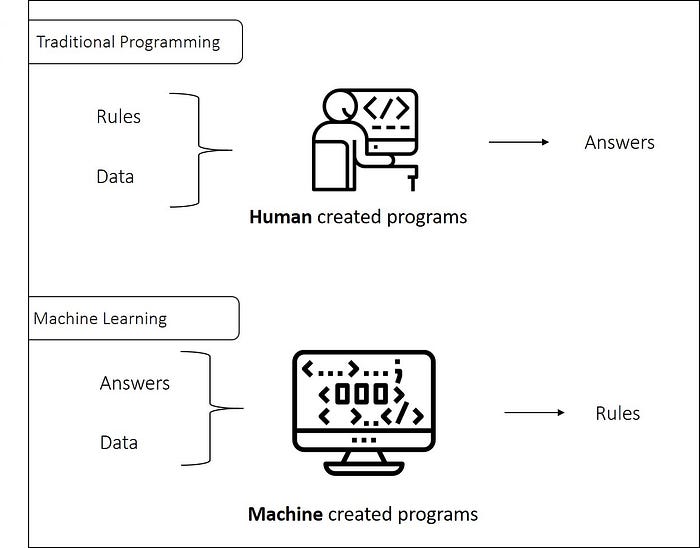
In traditional programming as we have known it human programmers would express rules in a programming language (for example C++, Java etc). The data introduced into the program would be assessed based on the rules that were coded in, and then the program would produce an answer based on the rules. However, machine learning introduces a new way to create a program which uses a different format from human created programs. In this sense, the data and the answers are introduced into a model which then determines the coding for the rules that would be needed to achieve the given answers. Machine created code or programs is desirable in circumstances where there are too many rules for human programmers to code in, as well as in circumstances where humans do not know the rules but have the answers (outcome) they are trying to understand from the data (input). With machine and/or algorithmically created programs (anthropomorphically ‘machine learning’), where it is the algorithm that is creating the rules, there are many ethical questions to discuss.

Likewise, there are important questions to ask about the labeling of answers and the data that is used to derive these algorithmically derived rules. One scenario is the use of machine created programs in judicial proceedings where the data and answers used reflect a biased system which discriminates against certain parts of the population. The rules that the algorithm will derive from the data and answers has the potential to perpetuate social injustice in the legal system and society at large. It is important for decision-makers assessing these tools to question how the rules derived by the machine created program can be adjusted to correct for social injustice in the algorithm.
Neural networks (also called neural nets) fall under the category of deep learning. The graphic in the following page illustrates how neural nets conduct image recognition — also referred to as ‘computer vision’.
The learning that occurs in neural nets is a back and forth pattern identification process using a probabilistic mathematical function where the final output is the value with the highest probability. In other words, learning can also be seen as the improvement of a mathematical function to produce an output whose probability is as accurate as possible.
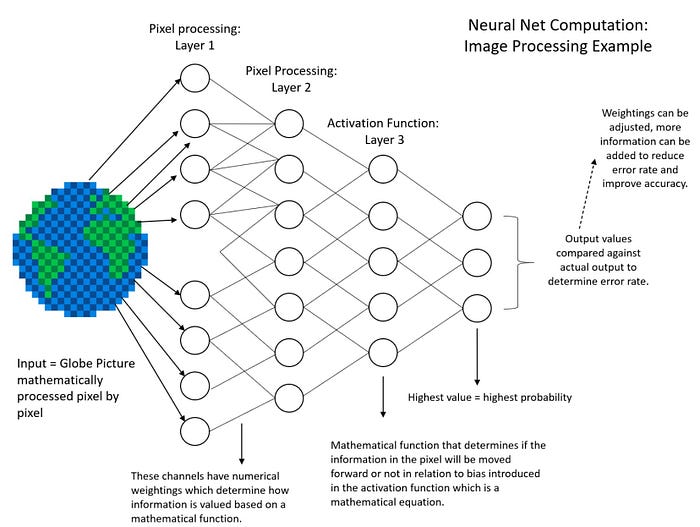
What this means is that decision makers and individuals should ask about the algorithm’s probability error rate and seek to understand the degree in which they can rely on the algorithm’s output. This will be particularly important for legal counsel to assess the liability an algorithm brings to an organization.
In this case, machine learning can be broadly deconstructed as a form of pattern identification and classification using statistical and mathematical models. The next section builds on the learning aspects of algorithms with the analysis use-cases.
ANALYSIS

Bloom’s Taxonomy of Educational Objectives identifies analysis as a middle level category in education. The analysis category in the taxonomy “represents the “breakdown of a communication into its constituent elements or parts such that the relative hierarchy of ideas is made clear and/or the relations between ideas expressed are made explicit.”[10]
When this taxonomy was developed in 1956, it specifically explored human education and the various educational goals on educating humans in the pursuit of education across different levels. The word analysis and analyze has been ascribed to AI-Systems as a catch-all to express that the algorithm processes data. However, up to this point, these words have been attributed to humans. Because algorithms process a wide range of data, it is important to de-anthropomorphize this usage so that users, decision-makers and non-technologists can converse about this algorithmic capability with more confidence. Some of the most common forms of human characteristics of analysis which are ascribed to algorithms is in their ability to: ‘see’, ‘listen’, ‘read’, and ‘sense’.

It is common for people (particularly children) to ascribe human characteristics about their AI assistants such as Amazon Alexa or Siri — saying that they are listening to them. In this instance the AI agent is not listening, however there is a convergence of sensors, algorithms and, more often than not, the cloud. The sensor is a microphone which picks up sound, the algorithm then processes that sound using ‘natural language processing’ (NLP) referring to automatic computational processing of human languages, which is part of the interdisciplinary field of computational linguistics.[11] This can either be processed on the device without the need to access the cloud for data (ie: edge-computing) or it can connect to the cloud through the internet to process the information.
Decision-makers need to understand the challenges and limitations of NLP, namely from a sensor perspective, a dataset perspective and an algorithmic processing perspective. If a decision-maker is assessing the utility of NLP to their organization they need to understand the sensors which will collect the data –what kinds of microphones are used? Are they on mobile phones? Is the area in which this data collected going to have noise that would impair the microphone from collecting accurate sound data? How important is the microphone quality to the use-case of the NLP software? From a dataset perspective, it is important for the decision maker to understand how robust the dataset is in relation to the intended use case. For example, if an AI-System is meant to transcribe judicial proceedings, does it have the legal lexicon encoded into the language corpora? Has the dataset been adjusted or controlled for colloquial or contemporary uses of certain words? Or foreign accents? Questions like this help manage the expectations of the algorithm producing a useful output. It also offers more space for co-creation between users of an algorithm and creators of an algorithm. From an algorithmic processing perspective NLP primarily uses statistical methods or ‘machine learning’ methods. Decision-makers should ask about the error rate in the statistical methods used as well as explore the different ‘machine learning’ methods that were used. For example, was it supervised, unsupervised, semi-supervised or reinforcement machine learning algorithms that were used? Each one of these methods opens a discussion for a conversation between technologists and decision-makers. The table below attempts to de-couple some of the commonly ascribed human traits in relation to algorithmic processing of information.

This de-coupling of human characteristics enables human decision makers to inquire more about the ideal and adverse conditions in which pixels can be processed. For example, if a company was exploring a video surveillance system around their factory and intended to use computer vision to identify human intruders, car plates or animals, there is a valuable conversation to be had about the cameras used and the exact location they are placed in combination with how the sun rises and falls around the building across the different seasons of the year. This change in lighting will affect the video captured, the pixels which are analyzed and in return how accurate the algorithm processes the pixels. In this scenario, deciding on an AI-System surveillance platform should also involve architects who understand buildings and light.
The de-anthropomorphization of algorithmic analysis of information as described in this section intentionally stopped short of the next level of algorithmic analysis that is anthropomorphized, which is knowledge. The next section decouples human knowledge from algorithmic Knowledge Representation which is the algorithmic packaging of data, and uncovers some philosophical questions that it poses.
KNOWLEDGE

As per section 1a of the definition of knowledge, when humans gain ‘familiarity through experience’ it is acquired “human” experience which is intertwined with social norms, culture and the human anatomical experience. As a non-human, an algorithm (or even an algorithm in a life size human looking robot), cannot understand what it feels for a woman to be sexualized on the street through cat-calls.[13]
Nor can the algorithm understand the chemicals of fear running through a woman’s brain as she assesses the size of the cat-calling perpetrator, his proximity to her and checks her perimeter to see if others are around who could help her in the event the encounter escalated to physical or sexual assault.[14] It would be difficult to represent this experience in algorithmic form. Similarly, an algorithm would never be able to conduct a probabilistic analysis on when a black female passenger will be asked to deplane because her outfit was deemed inappropriate.[15] That is because an algorithm would not be able to statistically represent a black woman’s gained experience of how it is to live at the intersection of misogyny and racism.
The reason for this this is because math and statistics do not explain perpetuated social injustice coupled with a long history of structural discrimination resting on widespread racism, the continued subjugation of women and not enough civic will or judicial accountability to correct it. Anthropologists, sociologists, psychologists and historians can attempt to explain the injustice, but it is a lived human experience. What algorithms do when they attempt to model or explain “knowledge” is called “Knowledge Representation”. Knowledge Representation divides knowledge into five types: (1) Declarative Knowledge, (2) Structural Knowledge. (3) Procedural Knowledge, (4) Meta Knowledge and (5) Heuristic Knowledge.[16] The graphic below helps visualize the different categories in algorithmic knowledge representation and contrasts it with how human knowledge is derived.
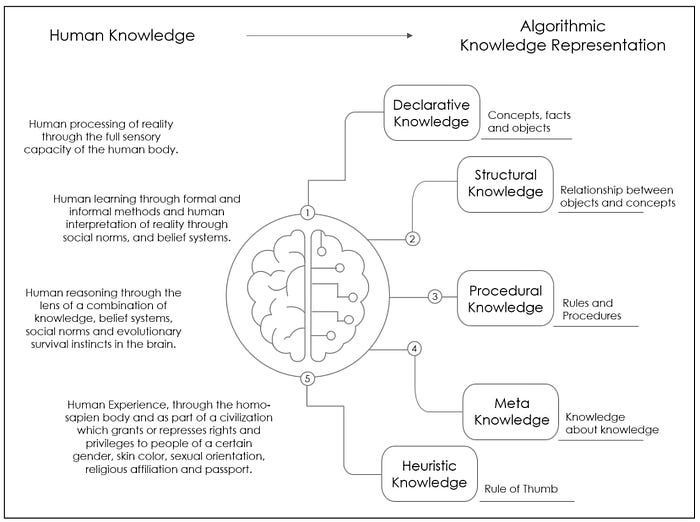
The data and datasets used to represent knowledge are vital to the knowledge representation fidelity that can be expected with the output of these algorithms. When breaking down knowledge representation decision makers have an opportunity to question the data used and assess whether it represents what the organization intends to use it for. or example, when procedural knowledge is used, it will be important to review the data source for the rules and procedures that will be encoded into the algorithm to make sure that they are up to date, that they also reflect the values of an organization and are fit for purpose.
However, rules and procedures are a small component of the sum of knowledge. Section 1c and 2a of the Marriam-Webster definition of Knowledge, reference knowledge as: “the circumstance or condition of apprehending truth or fact through reasoning” and “the sum of what is known: the body of truth, information, and principles acquired by humankind”. While it is challenging to represent this type of knowledge in algorithmic form, this essence of human knowledge, as part of the search for truth, is also being challenged by algorithms.

In a conversation with Thomas Friedman, historian and philosopher Yuval Harari eloquently tied this thread across time and space.[17] Harari chronicled human history to explain that at the beginning the ultimate source for truth and answers pertaining to human knowledge was the tribal elder, as they had gained the most human experience. Later, it became religious leaders, and more recently Harari explained that the answers we sought were inside us, as no one knows us better than we know ourselves. Thus, our personal human experience was validated as the source of truth and knowledge relevant to how we should perceive our world and proceed with our choices. He explained that this is currently being challenged by the new holder of knowledge — AI-Systems, which can process far more information than a human can; including information about oneself. Some algorithms today have the capability to be equal to, or better than, a human expert’s particular expertise. For example AlphaGo’s ability to be equal to or better than the best human Go player.
Another example is in the field of medicine where in 2018, the U.S. Food and Drug Administration approved the use of AI-Systems to detect diabetic retinopathy in adults who have diabetes.[18] An ophthalmologist may see a few thousand eyes across the entirety of their career, however an algorithm can process millions of retinal scans. While this may be compatible with portion 1a — 2 of the definition of the Marriam-Webster definition of knowledge, the creation of knowledge by humans is done through the perspective of the human experience, which is distinctly different than from algorithm’s output derived from ‘Knowledge Representation’.

What big data, endless data storage, cloud computing, internet accessibility and algorithms do, is they afford people the ability to outsource a part of their information storage and information processing. Which is an asset when thoughtfully done and a liability when consequences are not considered. The search for knowledge and answers increasingly brings people to an AI-System interface, instead of a human expert, whether it is Google, Siri, Amazon Alexa or a proprietary AI agent.[19] In fact, this is so prevalent that it has been coined the ‘Google Effect’ or ‘Digital Amnesia’ where people commit less information to memory because it is so readily accessible.[20] However, it does not mean that Google’s AI-Systems should be considered knowledgeable — humans are knowledgeable, algorithms offer “knowledge representation”.
With Knowledge Representation algorithms can aggregate data to produce content such as articles, music, screen plays and art among many other types of output. There is a valuable philosophical conversation to be had about the ability for an algorithm to be creative, ultimately just like any other creative output by humans — it will remain subject to human critique. However, regardless of the form of the output of an algorithm, the method and medium in which the information was proceeded is through a machine, through a mathematical or statistical model. In this sense, it can be seen as an integration of “Knowledge Representation” to form an original output. Decision-makers should be clear on the language they use when they describe the use of these types of algorithms to make sure that those across their organization do not develop unrealistic expectations about the knowledge that can be derived from an algorithm that offers a synthesis of the human knowledge the creators have been able to represent.
To avoid any mental misappropriation of value when algorithms are characterized as knowledgeable, algorithmic knowledge representation could best be understood as information fusion or synthesis which could be done with one type of data from one or multiple sources; or different types of data from different sources.
However, it is 1c of the definition of knowledge which states “the circumstance or condition of apprehending truth or fact through reasoning: COGNITION” that truly separates human knowledge capability from algorithmic capability. This is the essence of science, which involves the human capacity of discovering the universe in search of truth.

In ancient history the Babylonians and the Greeks were the first to pursue astronomy. They tracked the stars and the planets to develop the most accurate measurements of their era.[21] This pursuit of knowledge came through a combination of the observation of the movement of the stars, the curiosity to understand why and the motivation to pursue this knowledge and seek truth through cognitive reasoning. The same can be said for the discovery of gravity and other scientific discovery.
Today scientists, researchers, philosophers and students pursue knowledge through cognitive reasoning, fact searching and human curiosity. This has created and continues to create countless science breakthroughs.
AI-Systems have the potential to assist humans in their pursuit of knowledge and truth, however these systems are not able to have human desire, passion and curiosity which drives science and discovery. This is why it is important to decouple human knowledge from algorithmic knowledge representation.
Science is a form of knowledge that is a human endeavor as it is not just about curiosity and desire, but also includes morality and ethics. This is why the history of science is also one fraught with social backlash, upheaval and denial. It becomes more nuanced as morality and ethics do not stay static and evolve with cultural and social changes — another human endeavor.
It is important to make the distinction between human knowledge and algorithmic knowledge representation. Both have tremendous potential but only one is truly autonomous in thought and is capable of seeking the truth — humans.
In this sense, when incorporating algorithmic knowledge representation decision-makers will also need to think about the morality and ethics of the way they wish to implement algorithmic knowledge representation.
FORESIGHT

AI-Systems are increasingly sought after as a tool to anticipate the future. While humans who conduct foresight work are not always accurate, ascribing foresight to an algorithm can become a form of linguistic liability if humans leveraging the algorithmic output were to automatically perceive it to be accurate or automatically superior to human analysis. Just like the other human characteristics ascribed to artificial intelligence, it is important to linguistically de-anthropomorphize foresight to better understand the value proposition of algorithms. While there are many methodologies that humans use to conduct foresight, they generally fall under five broad categories: (1) Acquire Knowledge (2) Build Experience (3) Think hypothetically (4) Make predictions (5) Test Assumptions.[23]
The following table deconstructs the difference between human foresight and algorithmic foresight:
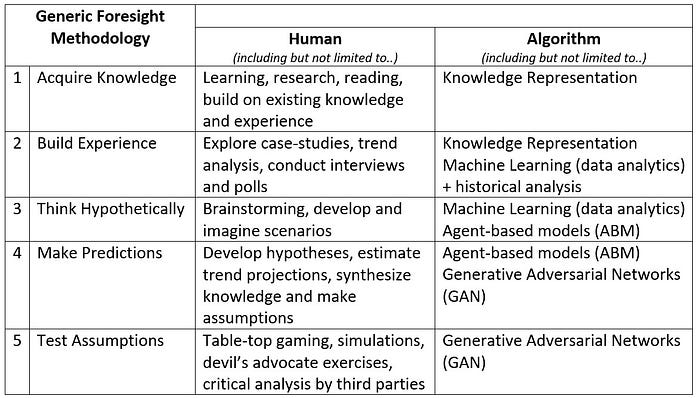
The outputs of both Agent-based models (ABM) and Generative Adversarial Networks (GAN) are derived from (including but not limited to) mathematical and statistical behavioral models.[24] Decision-makers do not need to understand the details of the models but they do need to understand how robust they are in the context of their use case. For example, at the beginning of the Coronavirus pandemic no algorithm (or human) was able to anticipate the acute and unprecedented demand for toilet paper, which was followed by the demand for flour and yeast to make sourdough bread at home; followed by the demand for kettle bells and then game-boards. During this period, many online retail sellers have acquired large sums of data about the spending habits during this pandemic. However, the shopping data of the COVID19 pandemic in 2020 may not be as useful in a different type of pandemic in 2027 or 2035. The next pandemic may be from a different form of virus that compromises the immune system in a different way resulting in different forms of prevention. It could be that the just-in-time supply chain problems experienced in 2020 are resolved before the next pandemic and the public does not feel the urge to hoard household necessities. The adaption to remote work and the rise of Virtual and Augmented Reality may change our workspace and our lifestyle by then which could create different needs during a future pandemic. While algorithmic modeling is useful, decision-makers should identify who is responsible and accountable to ensure that the models that are used to anticipate the future are not repeating the past, in a present that has since changed. Human analysts, anthropologists and sociologists should play a role in how Knowledge Representation is encoded and in the development of ABMs and GANs to help increase the accuracy of the algorithmic output.

Human, Machine or Human-Machine developed simulations are still limited by the human imagination, the data incorporated and the models used. It is important to remember that AI-Systems used for foresight offer algorithmic probabilities of what the future could be based on math, statistics and human assumptions in the development of the algorithm. It is about understanding and scrutinizing where algorithms can augment and accelerate human knowledge and where it is not possible.
There is tremendous value to be gained from algorithms that can process industrial amounts of big data across data types and sensors to help organizations gain greater situational awareness and posture themselves on how best to mitigate, leverage or manage the anticipated future. Decision-makers and lawyers will need to assess what aspects of algorithmic modeling represent a form of liability and develop a plan on how to minimize the risk with technologists, insurers and corporate policy.
DECISION-MAKING

In 2017, leading scientist Andrew Ng made the case for how AI-Systems were going to be the new electricity. He said, “Just as electricity transformed almost everything 100 years ago, today I actually have a hard time thinking of an industry that I don’t think AI will transform in the next several years.”[26] The analogy is unfolding right before our eyes, just as objects and spaces became electrified in the past from candles to light bulbs, stove kettles to electric kettles, so too we can see that the objects around us are becoming ‘smart’.
The growth of the Internet of Things (IoT) in homes, factories, cities and infrastructure is heralding a new industrial revolution of AI-system enabled processes through sensors, cloud and edge computing resulting in a ubiquitous, embedded form of assisted decision-making. Because decision-making has been a distinguishing aspect of human civilization and it involves an intricate assessment of human knowledge derived from human experience, social norms and belief systems, this topic merits a discussion about the human agency in decision-making.
This has profound implications not just for decision-makers and organizations as they leverage algorithms as part of their decision-making supply chain, but also for individuals. Today users of Netflix, Amazon or Instagram are accustomed to the suggestions for things to watch, books to read or items to buy based on the algorithmically derived preferences of the users.
In a Financial Times article Yuval Harari attempted to highlight that this type of assisted decision-making will become more pervasive in ways that will challenge our human agency as an individual and as a professional. He used actress Angelina Jolie’s double mastectomy in 2013 to illustrate how big data and algorithms can challenge human agency in the most intimate aspects of our lives. The reason Harari found Jolie’s decision to be the perfect textbook example of algorithms encroaching on human agency is because Jolie did not feel unwell when she underwent a double mastectomy procedure on her healthy breasts. Instead, a genetic test she took showed that she carried a dangerous mutation of the BRCA1 gene, and according to a statistical database “women carrying this mutation have an 87 per cent probability of developing breast cancer.”[27]
Access to DNA tests that would show these types of results are accessible online and doctors will need to be more informed about how these algorithms work to be able to respond to patients who would like to undergo an invasive surgery on a healthy body based on a probabilistic statistical analysis. Hospital administrators and technology decision-makers will need to learn how to help communicate the limitations of the algorithms to help their patients assume agency in the decisions they make about their health.
Algorithmic decision support has an important role to play across industries however, how it is incorporated is entirely a human endeavor. Understanding how data and algorithms work, what their limitations are, and how they make sense inside an organization’s (or person’s) decision-making supply chain should be a strategic priority. There are many ways algorithms can serve as important decision support points in the decision supply chain. Algorithms can provide information processing support for example in understanding financial market performance in comparison with previous years.[28] Algorithms can also perform (algorithmic) oversight in precision farming to make sure LED lamps are functioning as they should in relation to the plant type, moisture level and stage of growth.[29] Similarly, algorithms can contribute to sustainable energy consumption in factories.[30]
There are many more algorithmic use-cases in the decision-making process, however, its use must be understood as a decision support infrastructure — an infrastructure that needs to be maintained, insured, preserved and updated just as all other infrastructure.

The Merits of Anthropomorphic Restraint
The discussion in this paper was an attempt at looking past the problems of anthropomorphization in order to offer constructive alternatives to communicate the capabilities of AI-Systems without the lens of human characteristics.

Using non-anthropomorphic language when describing AI capabilities not only helps decision-makers, technologists, ethicists and lawyers develop a common understanding of the technology but it gives all parties agency to communicate their interests and concerns. Across industries, organizations are working diligently to harness the utility of AI-Systems to help make sense of ever-increasing amounts of big data. As more sensors come online and more data is able to be captured AI-Systems will unlock greater insight that had not been possible with human capabilities. It is exactly because of this that we need to practice restraint in the collective ways in which we describe AI-Systems and use the term “artificial intelligence”.
The consequence will be the blind glorification of AI-Systems and with time the increased pervasiveness and ubiquity of AI-Systems across our lives home, work and health it is very possible that AI-Systems could become a form of divinity. AI Ethicist Olivia Gamblin believes that in certain respects AI-Systems are already more than anthropomorphized and is concerned that it could become “revered with God-like status of knowledge and insight” because of its omnipresence and data analysis capabilities. She is concerned that if this happens ‘we’ as individuals and as a collective will not be able to question it — which is exactly what she says we need to do.
Speaking at the Internatioanal Telecommunications Union (ITU) AI for Good Global Summit, CEO of Danone, Emmanuel Faber shared his perspectives on how he sees AI challenges through the lens of the problematic mono-culture of produce. He notes that:

“The worst thing that could happen to humankind is that AI is actually standardizing, through data, the languages we are using. If you standardize the language you are sterilizing the thought. Because the language creates the thought. So how can you ensure that you design a system that accepts diversity, that accepts exceptions, that accepts to be self-disrupted, because that is the only way to maintain it in the service of life. So if I was going to invest in one aspect of AI that’s the one. Because I haven’t seen it cracked. And I am sure it has not. But that for me is an underlying topic [to make] AI successful. If we do not embed that ability, to respect diversity then we run a big risk of having the one kind of thought because everyone is thinking in the same language.” [31]
There is unbound potential in the use of AI-Systems to assist and augment the work and lives of humans.
Ultimately, a technology as important as AI-Systems, which will be employed across every industry and affect every single one of our lives, should be communicated in a way that does not de-humanize the human experience. It is my hope that this will be the start to a continued conversation about how we can best communicate the use cases and capabilities of AI-Systems in a way that allows for a more open and robust conversation on not just the opportunities, but the risks that need to be mitigated.

References
[1] “Her” Movie (2013) — https://www.imdb.com/title/tt1798709/
[2] “Ex-Machina” Movie (2014) — https://www.imdb.com/title/tt0470752/?ref_=nv_sr_srsg_0
[3] Amazon Alexa ‘Skills’ — https://www.amazon.com/alexa-skills/b?ie=UTF8&node=13727921011
[4] IEEE. Ethically Aligned Design. Version 2. https://standards.ieee.org/content/dam/ieee-standards/standards/web/documents/other/ead_v2.pdf
[5] OECD. AI Principles https://www.oecd.ai/ai-principles
[6] High-Level Expert Group on Artificial Intelligence. European Commission https://ec.europa.eu/digital-single-market/en/high-level-expert-group-artificial-intelligence
[7] Definition of Learn by Marriam Webster Dictionary — https://www.merriam-webster.com/dictionary/learn
[8] Ask the Know-It-Alls: How Do Machines Learn? Tom Simonite (2019) Wired — https://www.wired.com/story/how-we-learn-machine-learning-human-teachers/
[9] Definition of Analyze by Marriam Webster Dictionary — https://www.merriam-webster.com/dictionary/analyze
[10] Bloom’s Taxonomy. Vanderbilt University. https://cft.vanderbilt.edu/guides-sub-pages/blooms-taxonomy/
[11] What Is Natural Language Processing? https://machinelearningmastery.com/natural-language-processing/
[12] Definition of Knowledge by Marriam Webster Dictionary — https://www.merriam-webster.com/dictionary/knowledge
[13] The Effects of Exposure to Catcalling on Women’s State Self-Objectification and Body Image. (2017). Sophie Fisher1 & Danielle Lindner1 & Christopher J. Ferguson. https://www.christopherjferguson.com/Catcalling.pdf
[14] What happens to the brain during a sexual assault. Arkansas Coalition Against Sexual Assault. https://acasa.us/what-happens-to-the-brain-during-a-sexual-assault/
[15] Woman Required to Cover Up on American Airlines Flight Says Race Was a Factor. (2019). Neil Vigdor. https://www.nytimes.com/2019/07/10/us/black-woman-american-airlines-cover-up.html
[16] What is knowledge representation? https://www.javatpoint.com/knowledge-representation-in-ai
[17] How Thomas Friedman and Yuval Noah Harari Think About The Future of Humanity. New York Times Events (2018). https://www.youtube.com/watch?v=5chp-PRYq-w
[18] FDA permits marketing of artificial intelligence-based device to detect certain diabetes-related eye problems. US FDA. (2018). https://www.fda.gov/news-events/press-announcements/fda-permits-marketing-artificial-intelligence-based-device-detect-certain-diabetes-related-eye









